📊 SPSS数据分析中的P值与T值:统计显著性的双剑合璧 ✨
🔍 初识P值与T值:统计检验的核心指标
在SPSS数据分析的世界里,P值和T值就像两位默契的搭档,共同揭示数据背后的真相。T值(T-statistic)衡量的是样本数据与假设值之间的差异程度,而P值(P-value)则告诉我们这种差异是否具有统计学意义。🎯
T值的本质是样本均值与假设均值之间的差异,除以标准误差得到的比值。它的大小反映了效应量的强弱,而正负号则指示了变化方向。在SPSS输出中,T值通常出现在独立样本T检验、配对样本T检验等分析结果中。📈
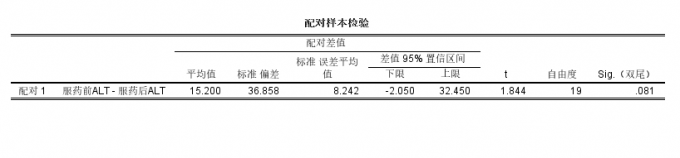
P值的奥秘在于它代表了在零假设成立的情况下,观察到当前结果或更极端结果的概率。SPSS中常见的P值标注方式包括"Sig."或"P-value",当这个值小于预设的显著性水平(通常为0.05)时,我们会拒绝零假设。🔬
🧮 SPSS中P值与T值的计算逻辑
SPSS通过复杂的算法为我们自动计算这些统计量,但了解其背后的数学原理能帮助我们更准确地解读结果:
-
T值计算公式:
T = (样本均值 - 假设均值) / (标准误差)
在独立样本T检验中,分母会考虑两组数据的合并方差 🤓
-
P值推导过程:
SPSS会根据计算得到的T值,结合自由度(df),在T分布表中查找对应的累积概率,然后根据检验类型(单侧或双侧)进行适当转换,最终输出P值。💡
小贴士:在SPSS中执行T检验时,软件会自动计算并输出这两个关键指标,但研究者需要正确设置检验参数和解读方向。👨💻
📝 SPSS输出结果的实战解读
当我们在SPSS中运行T检验后,输出表格通常包含以下关键信息:
- Levene检验:首先检查方差齐性,决定使用"Equal variances assumed"还是"Equal variances not assumed"行的结果 📋
- T值:绝对值越大,说明组间差异相对于组内变异越明显 ⚖️
- 自由度(df):影响T分布形状的重要参数,通常为样本量减1或减2 🧩
- P值(Sig.):判断结果是否显著的金标准,但要注意SPSS有时会显示".000",这表示P值小于0.001 ✨
示例场景:比较男女员工的平均工资,如果T=2.345,df=98,P=0.021(<0.05),则可以得出"在0.05显著性水平下,男女员工工资存在显著差异"的。💼
⚠️ P值与T值解读的常见误区
即使是有经验的研究者,也可能会陷入以下陷阱:
-
P值不是效应大小的度量
一个非常小的P值可能对应微不足道的实际差异,尤其是大样本研究时。SPSS使用者应同时关注效应量指标如Cohens d。🕵️♂️
-
T检验的前提条件常被忽视
SPSS不会自动检查数据是否满足正态性和方差齐性,研究者需要先进行探索性分析。正态性检验(如Shapiro-Wilk)和方差齐性检验(如Levene)应在T检验前完成。🔍
-
P值接近0.05时的武断
当P=0.049和P=0.051时,其实质差异微乎其微,但研究者可能做出截然不同的。更好的做法是报告精确P值并讨论其实际意义。🤔
🌟 提升SPSS分析质量的实用技巧
- 结果可视化:在得出P值和T值后,使用SPSS的图表功能绘制误差条形图或箱线图,直观展示组间差异 📊
- 效应量报告:除了P值和T值,在结果中补充报告效应量(如Cohens d、η²等),使研究更全面 🎯
- 敏感性分析:尝试不同的数据处理方法(如对数转换、剔除极端值等),观察P值和T值的变化趋势,评估结果的稳健性 🔧
- 多重比较校正:当进行多次检验时,使用Bonferroni校正等方法调整显著性水平,避免假阳性结果累积 🛡️
记住:P值和T值只是统计工具,真正的科学发现需要结合理论背景、研究设计和实际意义来综合判断。🔬
💬 网友热评
@数据分析小能手:
"这篇文章把SPSS的P值和T值讲得太透彻了!👏 以前只知道看P<0.05就欢呼,现在明白了还要看效应量和实际意义,真是醍醐灌顶~"
@科研小白的逆袭:
"作为刚接触SPSS的研究生,这篇文章拯救了我的毕业论文!💯 图文并茂的解释让我终于搞懂了输出表格里那些数字的含义,太实用了!"
@统计老司机:
"作者对P值误区的剖析太到位了!🎯 在学术界这么多年,看到太多人把P值神圣化,却忽视了数据分析的整体性。这篇文章应该列为研究方法课的必读材料!"
@心理学研究员Amy:
"大爱这篇文章的写作风格!💖 既专业又活泼,把枯燥的统计概念讲得生动有趣,特别是那些表情符号的运用,让阅读过程一点都不枯燥~"
@医学统计顾问:
"作为一个专业统计顾问,我完全赞同文章中的观点!🛡️ 尤其欣赏对P值接近临界点问题的讨论,这在实际研究中确实是个大坑,需要更多这样的科普!"
百科知识




